Coding Agents Need a Knowledge Factory, Not Just a Knowledge Base
As we automate more engineering, repeated agent mistakes become compounding costs. Teams need a knowledge factory that captures, tests, and retires guidance, not a static pile of rules.
TL;DR
Coding agents do not need a static knowledge base full of rules nobody fully trusts. They need a knowledge factory: a system that captures mistakes and interruptions from real work, turns them into reusable guidance, tests whether that guidance actually helps, and lets it decay when it no longer does.
Attribution is what makes that factory trustworthy. It tells you who learned what, from which event, and whether the lesson still deserves to shape future work.
A few months ago, repeated agent mistakes were annoying.
Now they are getting expensive.
If an agent only helps with implementation, a missed lesson costs one coding session. You correct it, swear at your terminal, and move on. But agents are moving upstream into specs, reviews, triage, refactors, and the other rituals that shape the work. Once they touch more of the lifecycle, the same missed lesson stops being local.
That changes the economics.
As automation spreads further across engineering, we can no longer afford to treat interruptions as one-off events. Every repeated correction becomes a tax. Every silent mistake becomes worse: no interruption, no friction, just bad reasoning flowing downstream with excellent formatting.
So the real question is no longer "how do I make the agent do this task?"
It is: how does a team turn agent mistakes into reusable, trustworthy knowledge instead of recurring costs?
The Old Bottleneck Was Implementation
I have spent the last months building and dogfooding infrastructure for coding agents with a few generous early testers. That has been useful for one reason above all others: it forced me to stop theorizing and start looking at where the time actually goes.
The answer is not flattering.
Most teams still respond to agent mistakes the same way they respond to human mistakes under time pressure: a PR comment here, a Slack message there, another line in AGENTS.md, maybe a team rule nobody remembers to remove later. It feels like progress because words were written down. But words written down are not the same thing as reusable knowledge.
What changes now is that the surface area is growing. When agents only generate code, weak memory is inconvenient. When agents also write specs, review code, and help shape decisions, weak memory becomes systemic. A bad lesson does not stay local. It leaks.
And that is where I think a lot of teams are optimizing the wrong thing. They are asking how to get more output from the model. The harder question is how to stop paying for the same confusion twice.
The harder question is not how to get more output from the model. It is how to stop paying for the same confusion twice.
Automation Raises the Value of Collective Intelligence
Each step below is not a feature checklist. It is a larger phase of the software lifecycle being delegated to agents.
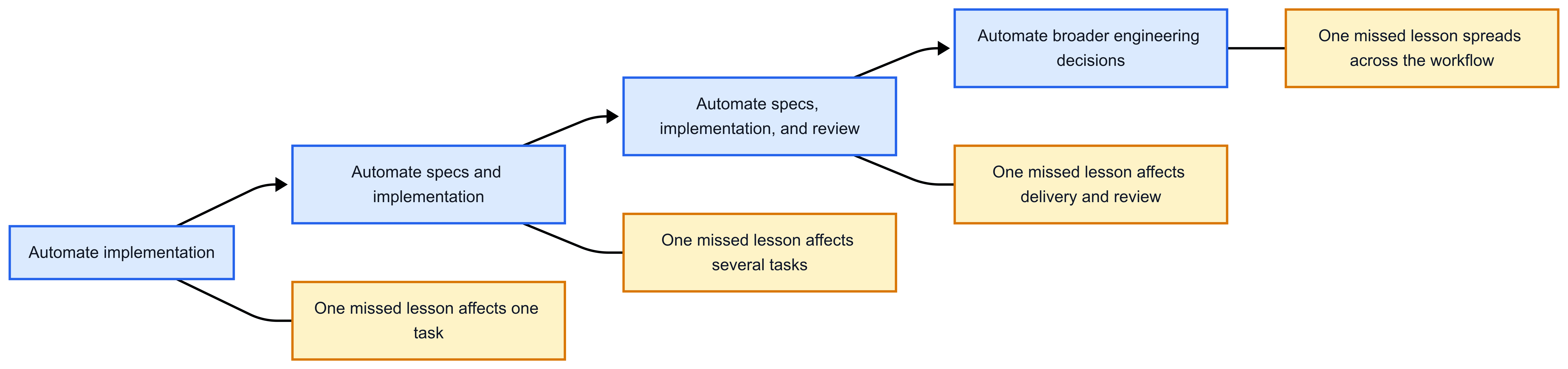
Blue shows how far automation extends across the lifecycle. Yellow shows how the blast radius of a missed lesson grows with it.
The point is not that agents make mistakes. Humans are not exactly famous for avoiding that either.
The point is that one missed lesson now has more places to leak into.
If a mistake is not captured properly, the team pays again later. Maybe next week. Maybe in another repo. Maybe through another agent using slightly different wording and making the exact same wrong assumption with fresh confidence.
This is why I keep coming back to the idea of collective intelligence. Not in the vague, "the future of work" sense. In the very boring engineering sense.
A team has collective intelligence when the next agent does not have to rediscover what the previous one already learned the hard way.
That only happens if three things are true:
- The lesson survives the session.
- The team can trust where that lesson came from.
- The right lesson shows up at the right time.
Without those three properties, you do not have collective intelligence. You have automation folklore.
A Knowledge Factory Needs Attribution
Most authorship debates around coding agents are really trust debates: who made the change, why they made it, and what reviewers should rely on. That is why people reach for proxies: commits signed with a human's key even though the agent wrote most of the change, PRs opened by a generic bot account, Co-Authored-By trailers that tell you almost nothing, platform-owned identities that blur three different agents into one vague "AI did it" bucket.
By attribution, I do not just mean who wrote the change. I mean who learned what, from which event, through which correction, and whether that lesson still holds.
That matters. A distinct agent identity, signed commits, and linked rationale make review less mystical and more concrete. They turn "who wrote this?" from guesswork into something closer to an answer.
But attribution matters for a bigger reason than review. In a knowledge factory, attribution is the quality-control layer. It is what preserves the chain between a lesson and the real event that produced it.
Knowing which agent made the change is necessary, but it still leaves bigger questions unanswered: has this issue happened before, was the correction later superseded, and did the explanation behind it actually hold up?
Still, it is the first primitive. It names the actor, and without that, the rest of the chain gets fuzzy very quickly.
What comes next is more interesting: preserving the interruption itself.
Not the polished summary after the fact. Not the cleaned-up "best practice" version. The actual moment where something went wrong, someone noticed, and a correction happened. That is the raw material.
Because the expensive part is not the original mistake. The expensive part is letting it remain isolated, so the next agent can make it again with the confidence of someone who has never suffered the consequences.
In a knowledge factory, attribution is the quality-control layer.
Session Memory Is Not Team Memory
An agent can remember plenty inside a context window, but that memory dies with the session; team memory has to survive, stay searchable, and remain attributable long enough to become reusable.
Otherwise the pipeline looks like this:
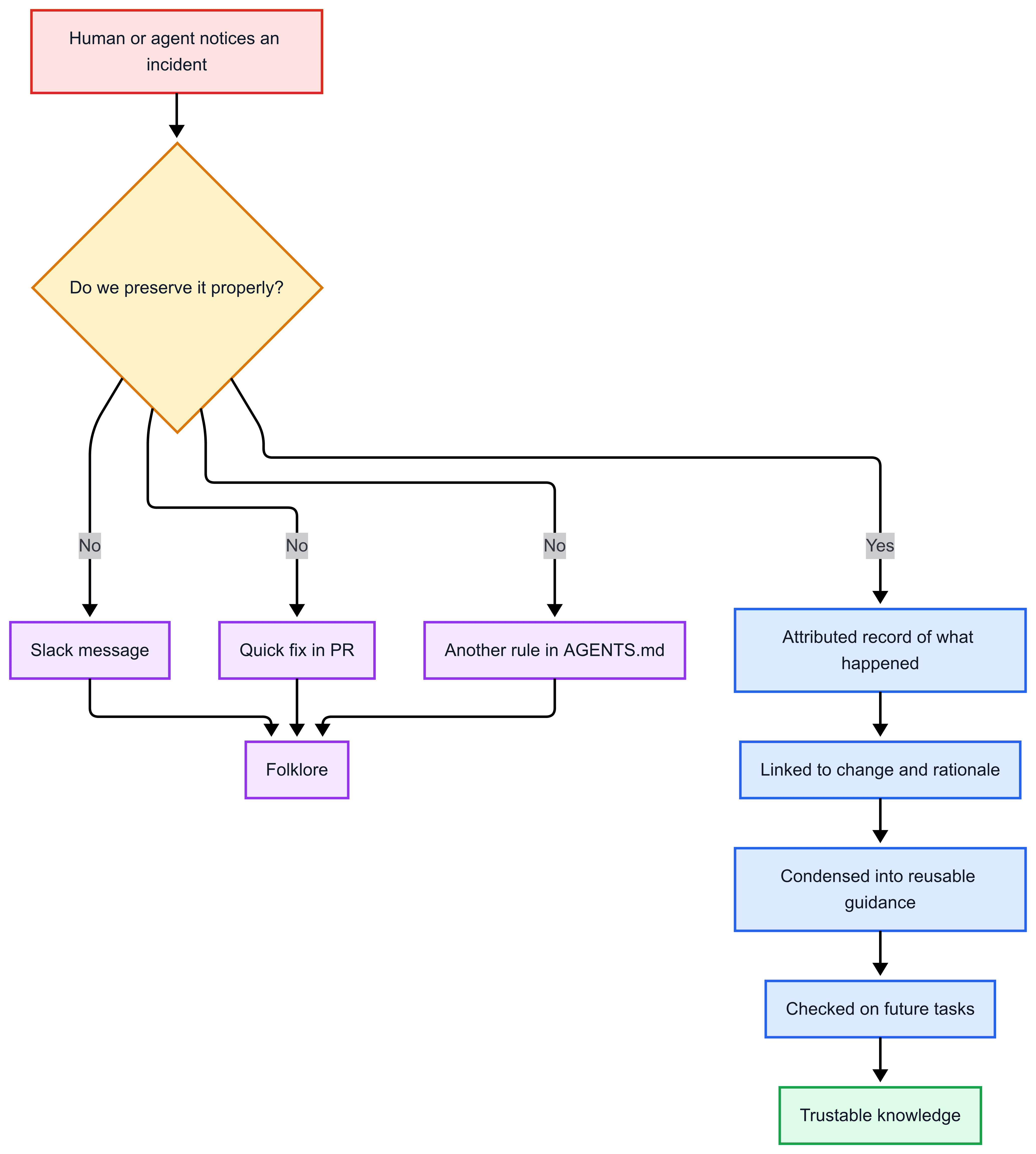
Red marks the interruption. Purple is folklore. Blue is traceable evidence. Green is trusted output.
That "folklore" box is doing a lot of work in modern teams.
You can feel it when someone says, "we usually do it this way," and nobody remembers why. Or when an agent keeps missing the same step, so the team adds another rule file, then another one, then another, until the project starts looking like it is managed by configuration sediment.
Say an agent updates an API surface but forgets to regenerate the spec and the generated clients. Review catches it, someone fixes it, and the release survives. In most teams, that lesson dies in a PR comment or turns into another vague rule in a file. In a knowledge factory, that interruption gets preserved with the actor, the event, the correction, and later evidence that reusing the guidance prevented the same mistake.
This is not a documentation problem. It is a knowledge-shaping problem.
The fix is not "write more rules." The fix is to preserve lessons as evidence first, then turn the good ones into reusable guidance second.
If you jump straight to polished guidance, you lose the incident that justified it. Then the advice may sound plausible, but nobody can tell whether it came from a real failure, an outdated assumption, or a temporary workaround.
A Knowledge Factory Must Test Its Output
A system like this needs to answer questions search alone cannot answer:
- Who learned this?
- From which event?
- Is it still valid?
- Was it later corrected?
- Did reusing it actually help?
That last question is easy to skip because it is inconvenient. But it is the difference between knowledge and "advice we keep around because nobody had time to challenge it."
In my own work, the split is simple: raw experience first, condensed guidance second, timely activation third. The condensed form is useful because nobody wants to feed an entire engineering log into every task. But once you compress knowledge, you still need a path back to the evidence, and you still need the right lesson to show up when it matters.
Otherwise you get the worst of both worlds: compressed enough to be injected everywhere, weak enough to verify nowhere.
That is why I think the real system we need is not just memory, and not just retrieval, and not just attribution. It is a factory:
- capture the interruption
- preserve who saw it and why it mattered
- turn it into reusable guidance
- surface that guidance when the situation calls for it
- test whether that guidance improves future work
- let weak guidance decay and strong guidance earn temporary trust
That is what turns mistakes into assets instead of liabilities, without pretending those assets should last forever.
And yes, that sounds slightly less sexy than "autonomous software engineering." But it is the part that determines whether the rest is useful or just expensive.
The Takeaway
We are not just automating coding anymore. We are automating larger parts of engineering.
That makes collective intelligence a practical engineering requirement. Every repeated interruption is a knowledge failure. Every silent error is worse. If a team cannot preserve what its agents learn, trace where that knowledge came from, and check whether it actually improves future work, then it does not have a knowledge factory.
Of course, none of this happens through good intentions alone. It requires technical infrastructure and habits that are still not common in most teams. I have been working on some of those building blocks already, and I'll come back to the practical side in the next article.
Until then, most teams do not have a knowledge factory.
They have recurring costs with better formatting.