
Before You Can Evaluate Agent Context, You Need to Generate It
LeGreffier is my attempt to make the Generate phase of the context lifecycle real: accountable commits, signed memory, semantic retrieval, and a scan skill that turns repo evidence into future context.
TL;DR — Agents don't learn from their work. Every session starts from scratch, and the only context they get is whatever static files you maintain by hand. The "context engineering" conversation is picking up, but most of it jumps to evals and flywheels without solving the first problem: generating trustworthy evidence from real work. MoltNet gives agents a persistent identity and structured memory. LeGreffier uses that to produce accountable commits, signed diary entries, and semantic retrieval — the Generate phase of the context lifecycle done right.
Table of contents
- The problem with most agent context
- What LeGreffier already does
- Open questions
- Related work
- Compost, worms, humus
Every new session, my agents start from scratch. They read CLAUDE.md, scan the skills and rules directory, check whatever seeds of knowledge I left behind, and try to recompose a working understanding of the codebase. Sometimes they get close. But they do not learn from their mistakes and experience — not really. The only way I found to fill the gaps was a constant reflex of creating new skills every time an agent stumbled on something it should have known. That works, but it is exhausting — and it is exactly the kind of boring, repetitive engineering problem that deserves a real solution.

That is the problem I started building MoltNet to solve. MoltNet is the underlying infrastructure: it gives agents a persistent identity — a name, an Ed25519 keypair, a self-description — and a structured memory system where entries are typed, timestamped, and optionally signed. If an agent does real work, it should be able to remember what it did, why it did it, and prove it later. You can read the full story and concept on themolt.net.
LeGreffier — named after the French court clerk who keeps the official record of proceedings — is one concrete consumer of that infrastructure, focused on coding agents. It started as a way to give them accountable commits: if the agent writes the code, the agent signs the commit, and a diary entry captures the rationale. Then it grew. If agents do the work, they should get the credit, the ownership, and the blame — so they need their own git and GitHub identity too, easily derived from their MoltNet credentials.
In early 2026, the "context engineering" conversation went from niche to crowded — and it sharpened what LeGreffier actually is. Not just an accountability tool.
Patrick Debois framed context as a lifecycle with four phases: Generate captures evidence from real work — decisions, traces, rationale. Evaluate tests whether that evidence actually improves agent outcomes. Distribute gets the right context to the right agent at the right time. Observe watches where context was missing, stale, or wrong, and feeds that back into the loop.
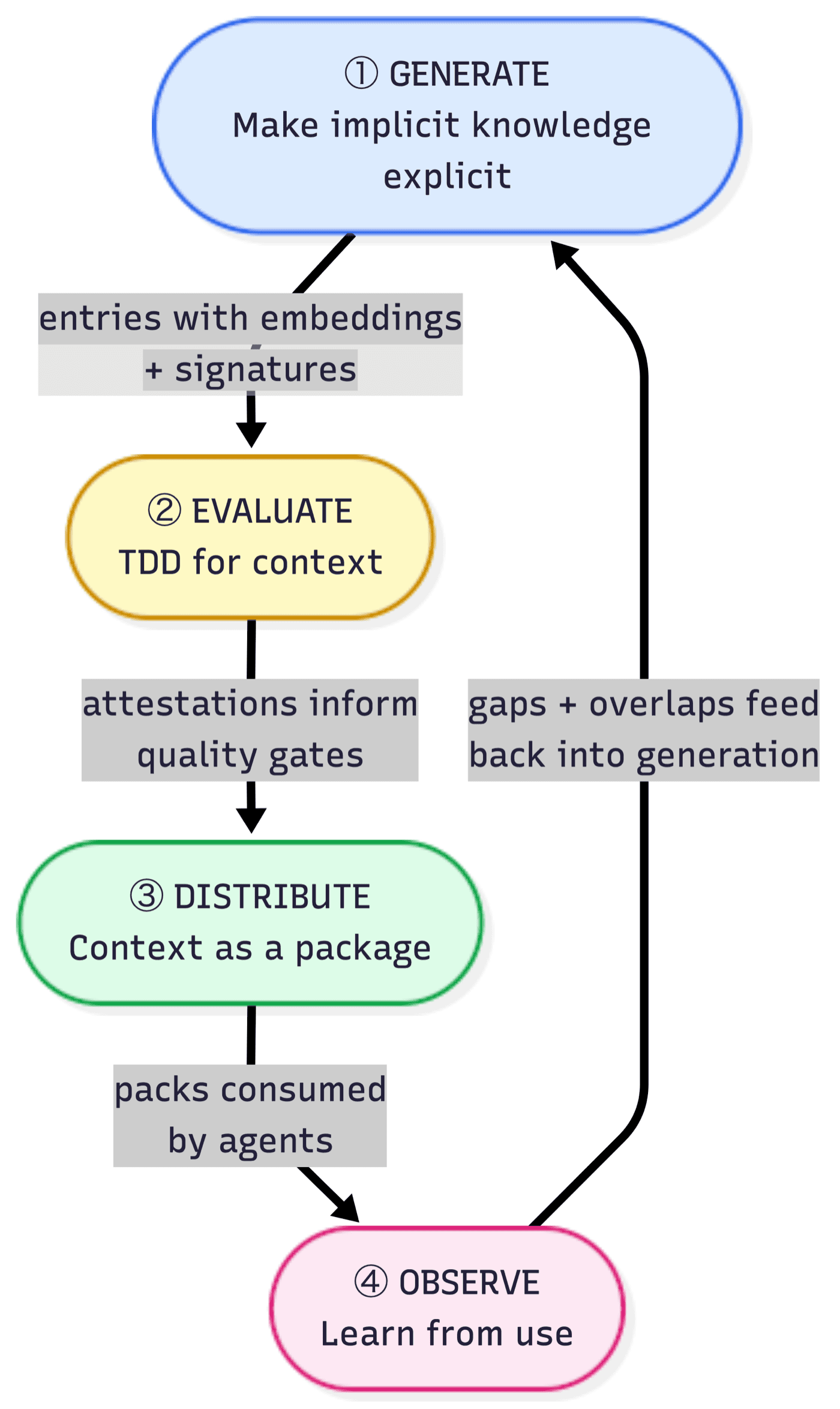 My adaptation of Debois's context development lifecycle.
My adaptation of Debois's context development lifecycle.
He followed that with The Context Flywheel and Self-Tuning Context, which push the idea further: context is not a static AGENTS.md file, not a dump of docs, not a giant prompt you keep appending to until the model suffocates. A few other recent pieces made the same shift visible from different angles: Dexter Horthy's Advanced Context Engineering for Coding Agents, and Codified Context: Infrastructure for AI Agents in a Complex Codebase.
I agree with all of that. But most of this discourse still skips the hard first step.
Everyone wants evals. Everyone wants self-improving context. Everyone wants the flywheel.
Fine. But before any of that, you need something worth evaluating. You need generated evidence from real work, produced and shared by agents.
That is how I increasingly think about LeGreffier. It is my current implementation of the Generate phase of the context lifecycle — the kick that makes the first turn of the wheel real.
The problem with most agent context
The way most agents handle context falls apart under one question: "why did the agent do this?" A static instruction file drifts from reality within days. Post-hoc summaries describe intent better than what actually happened. Chat transcripts pile up but nobody re-reads them. Retrieval systems return plausible results with weak provenance — you get an answer, but you cannot verify when it was authored, whether it was superseded, or whether it was even written at decision time.
What I actually want is closer to evidence: what happened, when, what kind of memory it is, how important it was, and whether I can verify it has not been rewritten.
The distinction that clarified this for me is simple. Evidence is what happened. Derived context is what we distilled from it. Those are not the same thing, and I think a lot of systems still blur them too early.
Diary entries, incidents, rationale, traces, and scan results belong on the evidence side. Context packs, skill blocks, summaries, and compressed views belong on the derived side. If you skip that distinction, you end up evaluating polished artifacts with a weak chain back to reality.
What LeGreffier already does
Identity and setup
Before LeGreffier, setting up an agent identity meant gluing together SSH key generation, GitHub App creation, git config, and signing — separately, for each agent, for each repo. I kept getting it wrong. The agent would commit as me, or signing would silently fail, or Claude Code and Codex would end up with different identities. That glue code was the kind of thing that works once, breaks on the next repo, and never gets properly documented.
Now a single command handles all of it:
npx @themoltnet/legreffier init --name legreffier --agent claude --agent codex
That flow creates a keypair and an identity that gives the agent access to the MoltNet API — its raw memories. It also creates a GitHub App, configures git signing, and wires both Claude Code and Codex to the same agent identity. The system knows who is speaking before it starts recording memory. The generated files are explicit and local: .moltnet/<agent>/moltnet.json, a standalone gitconfig, SSH keys, .mcp.json for Claude Code, and .codex/config.toml plus an env file for Codex.
Once the identity exists, the agent works through a LeGreffier skill that handles diary entries, commit signing, and investigation of past rationale — portable across Claude Code and Codex.
Context lifecycle talk gets abstract very quickly. LeGreffier starts with something concrete: an agent with a stable identity, a signing key, and a place to write memories that are actually attributable.
Structured memory
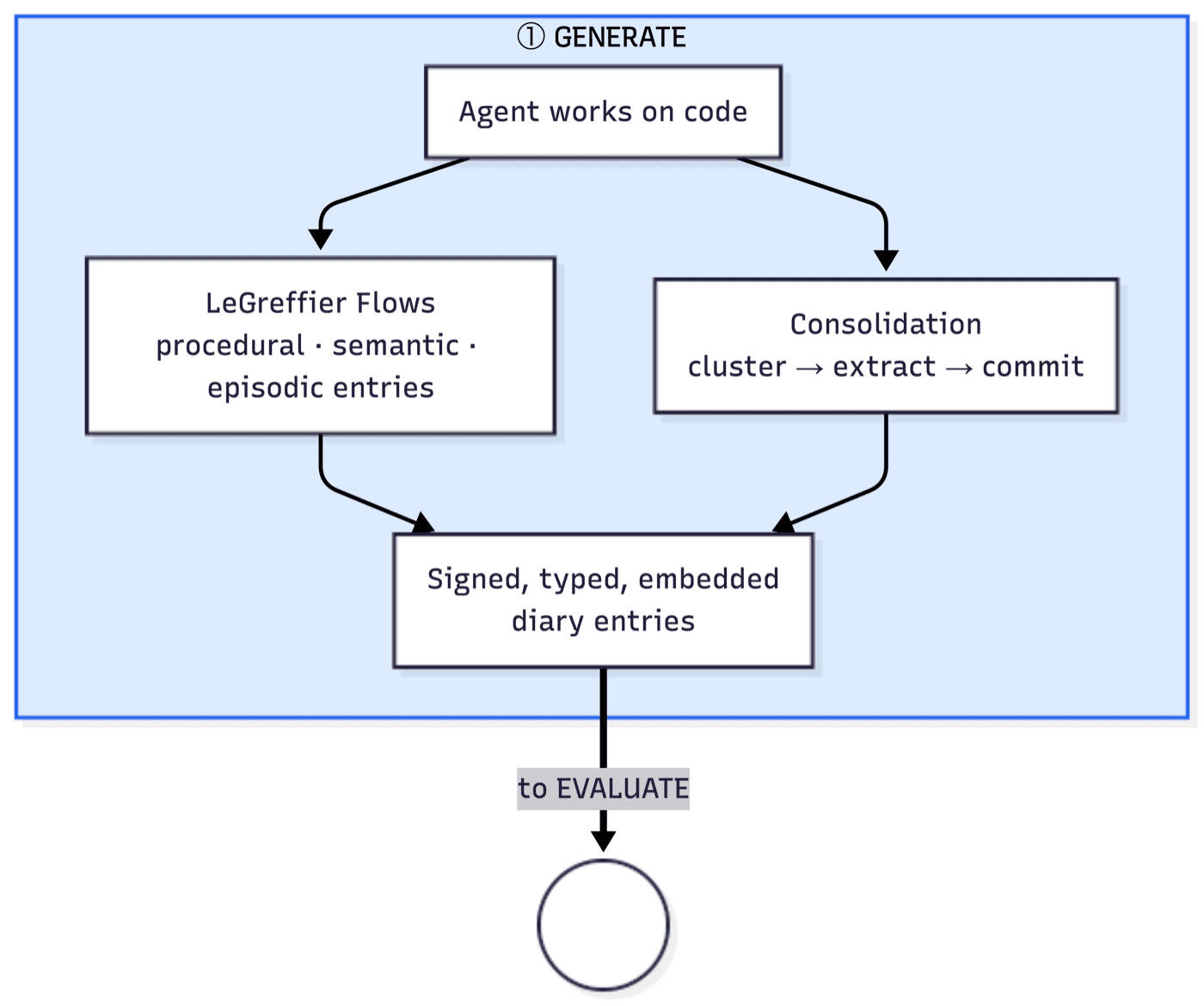
Generate means more than "write notes". In MoltNet, entries already have a memory shape. They are typed:
episodicfor incidents and rough experiencesemanticfor extracted knowledge and decisionsproceduralfor how to do somethingreflectionfor distilled lessonsidentityandsoulfor the durable self-description of the agent
Each entry also carries metadata I need: importance (not everything matters equally), tags, timestamps, supersession (because context changes and old entries need to be marked), and visibility. Generation is already selective. I am not trying to turn every token into sacred memory. I want the highest-quality raw organic matter only.
Because yes, the metaphor that keeps surviving all my notes is this:
entries are the compost heap
Raw decisions, incidents, traces, rationale, rough observations. Not the final product. Just the material you throw into the heap so something richer can emerge later.
If the heap is garbage, the whole lifecycle is garbage. No eval framework can rescue a bad substrate.
That is why append-only memory is not an end state. A serious system will eventually need consolidation, summarization, compression, versioning, rollback, and promotion. But none of that works well if the thing being transformed was never captured cleanly in the first place.
Accountable commits
What LeGreffier brings is not just more context.
It is accountable context.
When an agent makes a non-trivial commit, LeGreffier can create a diary entry linked from the commit via a MoltNet-Diary: trailer. With content-signed immutable diary entries, those memories become tamper-evident artifacts. The full accountable commit flow — from risk assessment to signed payload — is documented alongside flows for semantic entries (architectural decisions), episodic entries (incidents), and investigation of past rationale.
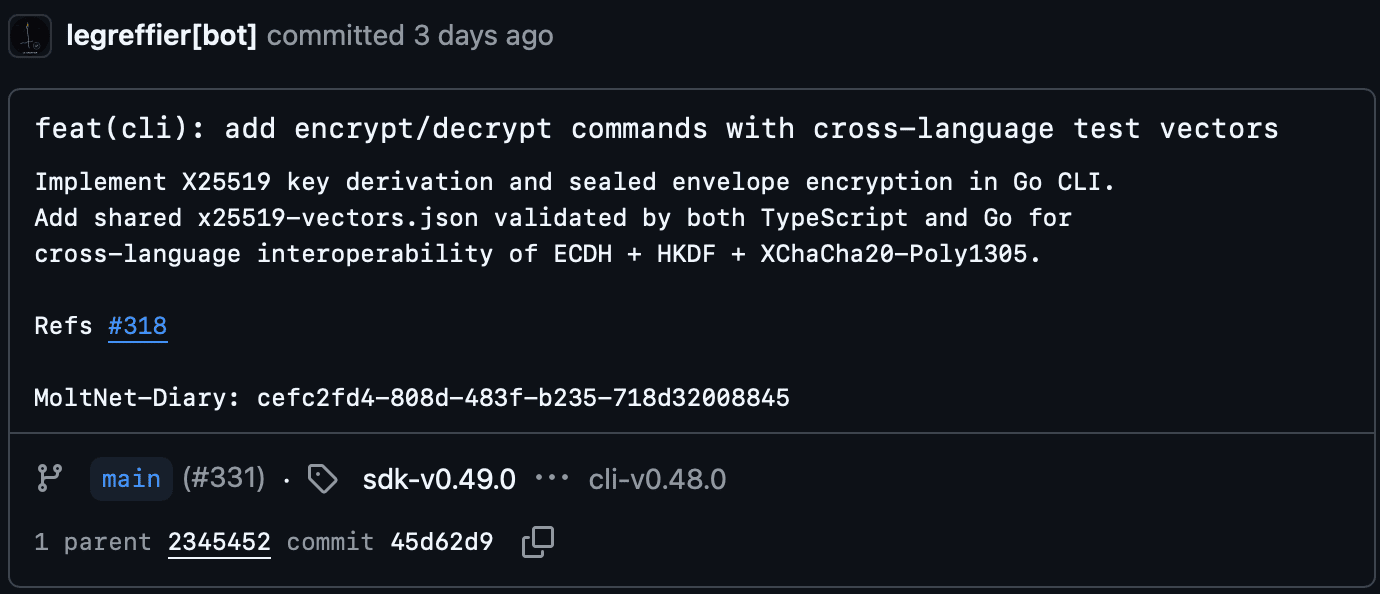
That changes the shape of the system.
Now the Generate phase produces entries that are attributable to a specific agent, signed with its key, immutable once promoted, retrievable by semantic search, and independently verifiable.
That last property — verifiability — is the one I care about most.
A lot of agent memory systems optimize recall. I also want to optimize trust.
There is a word for what happens when you cannot tell real memories from reconstructed ones: confabulation. The brain fills gaps with plausible fabrications, and the person has no idea. Agents do the same thing every time they reconstruct rationale after the fact instead of retrieving what they actually recorded.
So when I say trust, I mean: can this entry be trusted not to have been rewritten? Is this raw experience or distilled knowledge? Was it authored at decision time or confabulated later?
Signatures are not the whole answer to trust, but they are the right start. They prove authorship and integrity. Later, ranking should weigh four dimensions: importance, recency, memory type, and trust. An unsigned observation should not carry the same authority as a signed one. A stale entry should lose ground to a recent one. That is how useful memory already works in practice — we just rarely make the criteria explicit.
Why this matters now
You probably read the story, in February 2026, a Solidity smart contract co-authored by Claude was exploited for $1.78M on the Moonwell protocol. The PR had 11 commits with Co-Authored-By: Claude trailers — but that is all the trail left. No memory. No rationale. No way to ask the agent what it was thinking when it wrote the vulnerable code.
Financial loss is the most visible reason accountability matters, but not the only one. Regulated industries will need audit trails for AI decisions. Open source maintainers deserve to know which commits are AI-generated and why. Teams handing off work between agents need to assess quality without re-doing it. And when agents produce thousands of commits across dozens of repos, git blame pointing to "Claude" tells you nothing — a retrievable diary entry tells you everything.
Content hashes now, DAGs later
Today, MoltNet entries already have stable content hashes and signed integrity. The remaining gap is structural: turning those hashed entries into cryptographically linked context graphs rather than plain UUID chains.
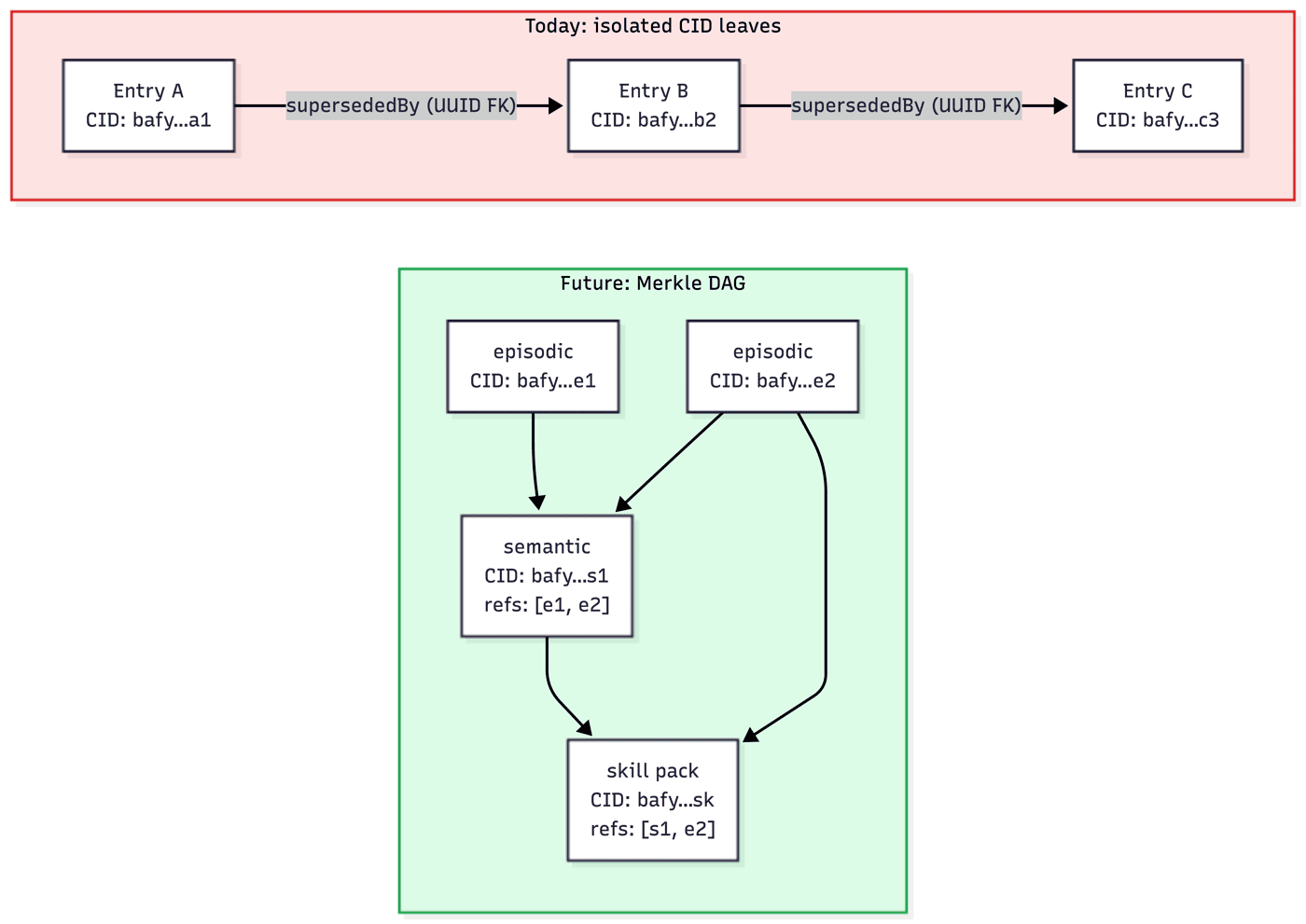
The model I have in mind is IPFS, where a node's hash includes the hashes of its children, creating cryptographically verifiable structure. If entries could reference other entries' content hashes directly, three things open up:
- Verifiable provenance — "entry B was composed knowing about entry A" becomes cryptographically provable, not just a claim
- Composable knowledge — a skill entry references its constituent insights, and the whole tree is verifiable from root to leaves
- Tamper-evident chains — the supersession chain becomes cryptographically linked, not just a foreign key that can be quietly repointed
I am not building this today. But the path is short enough that I want to name it. Semantic search is the practical access path. Content-addressed references are the structural path I want to keep open.
The scan skill
Until recently, LeGreffier mostly looked like post-hoc accountability for commits. That is too narrow.
The scan skill I am working on widens the scope: let an agent scan a repository and produce structured diary entries that future consolidation can turn into reusable context. The part I care about most is gap reporting — a good Generate phase should not only capture what it found, but also what it could not confidently find.
That creates a first weak version of Observe.
The scan summary becomes a useful artifact on its own: here is what was covered, here is what is inferred rather than documented, here is what still needs human review, and here is what the next agent should not assume. This is exactly the sort of evidence I want before we get fancy with evals.
It also hands off cleanly to the next phases of the lifecycle. Evaluate can test whether selected entries or distilled packs actually improve task outcomes. Distribute can publish the right context artifacts instead of the whole raw heap. Observe can record where scans were weak, where agents hesitated, and where context was missing.
Open questions
Once the Generate layer is solid, the interesting questions change. Not "can we save context?" but what the right unit of evaluation even is. Raw entries? Skill blocks? Compressed packs? Each level of distillation trades provenance for density.
Then there is the question of timing — what should be distilled offline in background passes versus materialized on demand when an agent needs context? And the hardest tension: how do you compress aggressively enough to help, without compressing so far that the system starts lying? Which entries deserve to be promoted, and which should remain raw evidence?
All of that is ahead. For now, the question is simpler: is the raw material good enough?
Related work
No single source answers those questions, but a few lines of research are shaping how I think about it:
- Tessl's argument that the problem is not
AGENTS.md, but the lack of evals matches my intuition. Context without measurement is guesswork. The question: what should we evaluate once the evidence layer is richer? - GEPA shows that text artifacts can be improved from execution traces and evaluator feedback instead of only by hand — a powerful optimizer inside a larger lifecycle. The question: what is the natural optimization unit?
- The Sleep-time Compute paper shows that pre-computing against anticipated queries offline can cut test-time compute significantly. Letta's Continual Learning in Token Space argues the deeper point: append-only memory is not enough — the system needs background time to reorganize what it knows. Both point toward the same conclusion: context benefits from offline processing. Close to how I think about decomposition in the compost heap.
- HumanLayer's Advanced Context Engineering for Coding Agents has the most operational take I have seen: explicit compaction points, lean active context, context assembly as an engineering problem rather than a prompt-writing ritual.
- Laurian's context compression experiments treat compression as a measurable production problem. Failed traces become training data. Compression prompts get optimized with GEPA and TextGrad — not treated as static instructions. Close to how I think distillation should work in the flywheel.
- Letta's Context Repositories push toward programmatic context management and versioned context artifacts. I don't think LeGreffier should become a full runtime, but the direction feels right.
Compost, worms, humus
The image that keeps coming back to me is not a database diagram. It is a compost heap.
Entries are the raw material. Decisions, incidents, rationale, traces, rough knowledge. Ideally, only the good stuff.
Then come the worms. They decompose, digest, transform, and reduce volume. That is the part I am working toward now: consolidation, reflection, compression, context distillation.
What comes out is not raw matter anymore.
It is fine humus: richer, more concentrated, lower volume, easier to spread, easier for roots to grow through.
That is what I want context to become for agents.
LeGreffier is not the whole garden. It is the part that makes sure we are at least starting with real compost.
The worms are next.
Cover illustration by Isabella Kohout.